
本周,我们发布了 Astro 5 的第一个 Beta 版本,其中包含一种全新的 Astro 内容处理方式。本文将深入探讨内容层 API,展示其工作原理以及如何使用它来构建您的网站。
Astro 为创建内容驱动的网站而生。虽然它现在也可以用于构建各种动态应用程序,但对于围绕大量内容构建的网站来说,它仍然是最佳选择。从使用 Starlight 构建的全功能文档网站,如 Cloudflare 和 StackBlitz,到为 Porsche 和 Netlify 等品牌打造的精美营销网站,每天都有数百万用户正在体验使用 Astro 构建的快速且可访问的网站,成千上万的工程师喜爱业界最佳的开发体验。
在 Astro 2 中,我们引入了内容集合(Content Collections),作为一种强大的新方式来组织本地内容、以类型安全的方式构建并扩展到数千个页面。内容集合为 Markdown 和 MDX 等本地文件提供了业界一流的开发体验,但我们听取了您的反馈,您希望所有内容(包括远程 API)都能享受到相同的优势。同样清楚的是,尽管许多人正在构建拥有数千个页面的网站,但我们的内容集合 API 在扩展到数万个页面时遇到了困难,表现为构建速度变慢和内存占用过多。
今年六月,我们分享了关于通过全新的内容集合类型(由内容层 API 提供支持)解决这些问题及更多问题的早期计划预览,该 API 提供了您所要求的灵活性。我们设想将集合扩展到不仅仅是 src/content 中的文件,而是允许您从任何地方加载内容。我们一直在测试能够扩展到前所未有规模的集合。自 Astro 4.14 中的首次实验性发布以来,我们一直致力于稳定这一新 API,以期在 Astro 5 中发布。
什么是内容层
内容层 API 是您所熟悉和喜爱的内容集合的未来。它允许您在构建网站时从任何来源加载数据,然后通过简单、类型安全的 API 在页面上访问它。
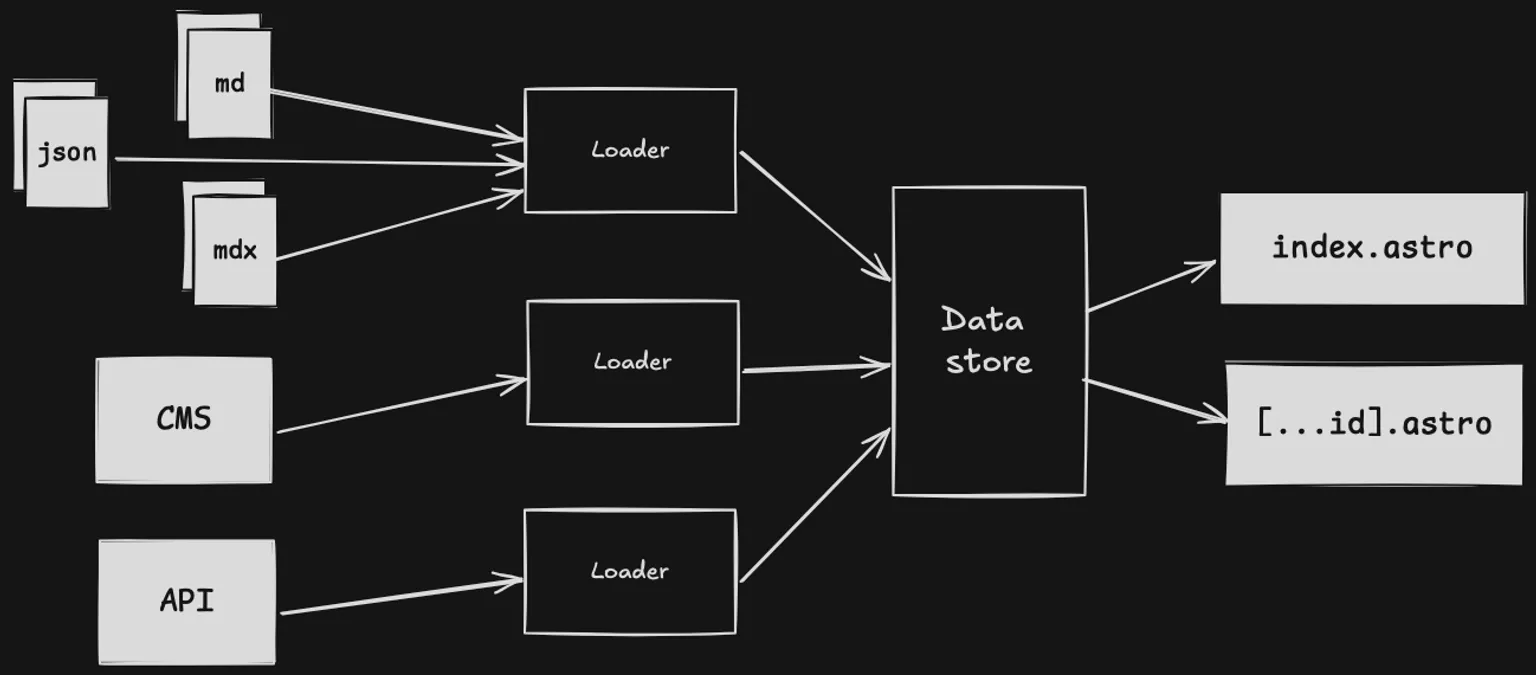
内容层 API 不关心您的数据存储在哪里。一个集合可以是本地的 Markdown 文件,另一个可以调用 API,还有另一个可以存在于您文件系统的其他位置。使用与以前相同的 getEntry() 和 getCollection() 函数,您可以从同一页面的多个来源加载数据。性能没有损失:Astro 会在构建之间本地缓存数据,这意味着更新速度快,并且可以最大限度地减少所需的 API 调用次数。当然,所有内容仍然是类型安全的,TypeScript 类型会根据您的 schema 自动生成。
如果您之前使用过内容集合,您会认出以下许多概念和术语。事实上,我们并没有对项目中使用集合的方式进行太多更改!**集合**仍然是我们对共享公共 schema 的一组条目的术语。每个条目都有一个唯一的 ID。它类似于关系数据库中的一个表。
但现在,每个集合都使用一个**加载器**(loader),它定义了如何加载条目以填充该集合。加载器可以是一个返回条目数组的基本内联函数,也可以是一个处理自身缓存和数据存储的更高级对象。第一批加载器已经作为 npm 上的模块发布。
每当您的网站构建时,就会调用每个集合的加载器,然后更新本地**数据存储**。您可以使用熟悉的 **getCollection()** 和 **getEntry()** 函数查询该数据存储。这在构建时用于预渲染页面,或在使用按需适配器时在服务器渲染期间完成。在每种情况下,都可以获得相同的数据,即构建时的数据快照。这里需要注意的重要一点是,**数据存储只在构建时更新:部署的网站无法更改数据存储。** 如果数据源需要更新集合,它必须通过触发新的构建来实现。
创建集合
在 src/content/config.ts 中定义您的内容集合,如果您之前使用过集合,则应该已经有了这个文件。新的 loader 属性定义了数据源,它可以像返回项目数组的异步函数一样简单
import { defineCollection, z } from 'astro:content';
const countries = defineCollection({ loader: async () => { const response = await fetch('https://restcountries.com/v3.1/all'); const data = await response.json(); // Must return an array of entries with an id property, or an object with IDs as keys and entries as values return data.map((country) => ({ id: country.cca3, ...country, })); }, // optionally define a schema using Zod schema: z.object({ id: z.string(), name: z.string(), capital: z.array(z.string()), population: z.number(), // ... }),});
export const collections = { countries };然后,这些数据将像以前一样在您的 .astro 组件中可用
---import type { GetStaticPaths } from 'astro';import { getCollection } from 'astro:content';
export const getStaticPaths: GetStaticPaths = async () => { const collection = await getCollection('countries'); if (!collection) return []; return collection.map((country) => ({ params: { id: country.id, }, props: { country, }, }));};
const { country } = Astro.props;---
<h1>{craft.data.name}</h1><p>Capital: {craft.data.capital}</p>我们对在页面上查询和渲染数据的这种体验已经非常满意,所以我们将注意力转向了该过程背后的机制。让我们深入探讨内容层 API 如何组织、管理和使用您的内容!
内容层生命周期
当运行 astro build 或 astro dev 时,每个集合的加载器会并行调用。这些加载器会更新其各自作用域的数据存储,数据存储在构建之间会保留。
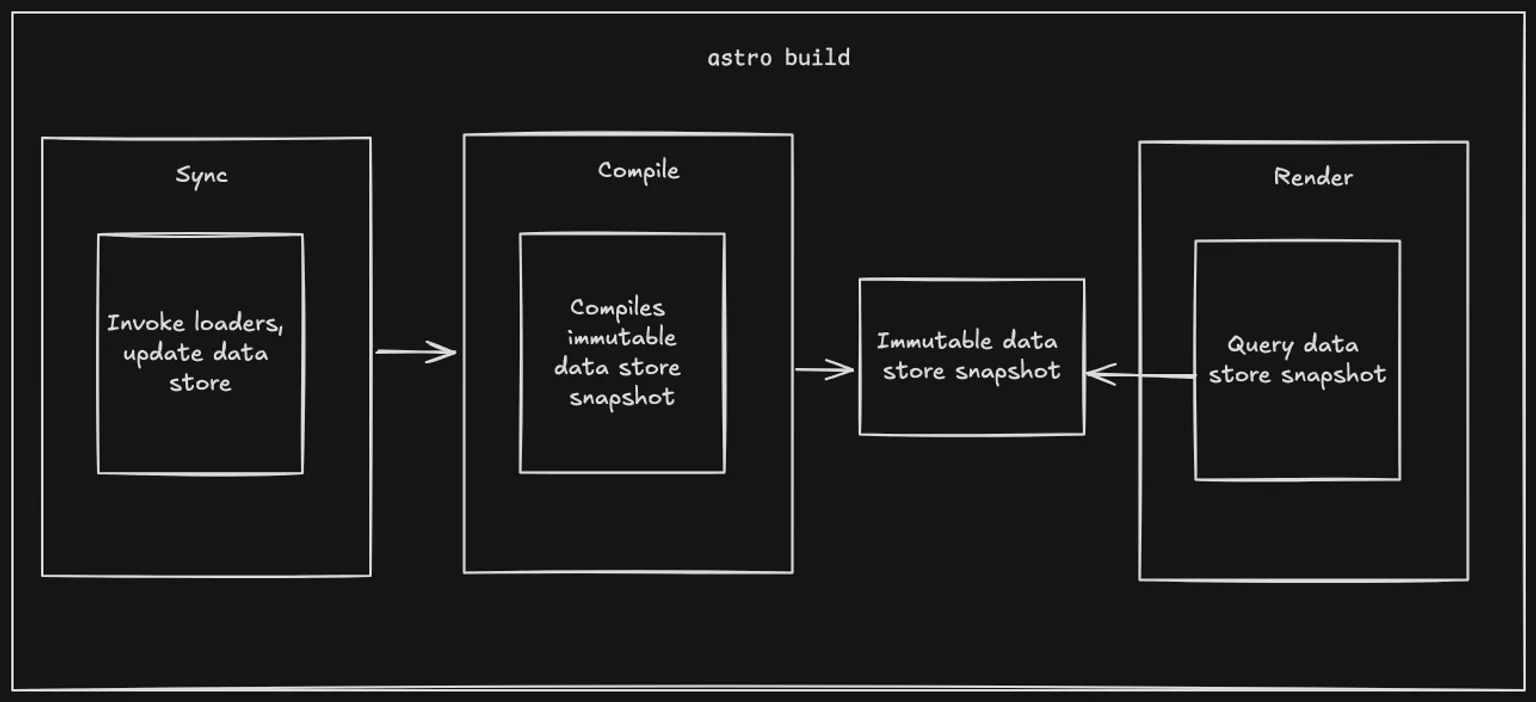
Astro 组件和页面随后可以使用 getCollection 或 getEntry 查询数据。数据在此时是不可变的,因此所有页面都在查询相同的快照,该快照在构建时编译。这适用于页面在构建时预渲染,或按需进行服务器渲染。这里需要注意的重要一点是,**数据存储只在构建时更新:部署的网站无法更改数据存储。** 如果数据源需要更新集合,它必须通过触发新的构建来实现。
尽管在生产环境中是不可变的,但在运行 astro dev 时,数据存储可以通过 s+enter 热键或通过集成进行按需更新。它们可以通过多种方式实现这一点,例如注册一个开发刷新端点或打开一个套接字连接到 CMS 以监听更新。
加载器的工作原理
第一个示例展示了如何构建一个简单的内联加载器,但您不必止步于此。借助对象加载器 API,您可以构建功能更强大的加载器。对象加载器通过数据存储对象与内容层交互。这是一个作用域限定为单个集合的键值存储。集合只能访问自己的条目,但对其拥有完全控制权。如果加载器知道其数据源未更改,则可以完全跳过更新,或者只更新已更改的条目。
内容层 API 提供了一些工具来简化此操作。首先是元数据存储,它可用于存储任意值,例如“上次修改”时间或同步令牌。比较这些值将允许加载器执行条件 API 请求或使用增量同步 API 等操作。
此示例展示了如何使用 RSS 提要加载器执行此操作。它将上次修改的标头存储在元数据存储中,然后在下次加载提要时使用它来发出条件请求
export function feedLoader({ url }: FeedLoaderOptions): Loader { const feedUrl = new URL(url); // Return a loader object return { // The name of the loader. This is used in logs and error messages. name: 'feed-loader', // The load method is called to load data load: async ({ store, logger, meta }) => { // Check if there's a last-modified time already stored const lastModified = meta.get('last-modified');
// If so, make a conditional request for the feed const headers = lastModified ? { 'If-Modified-Since': lastModified } : {};
const res = await fetch(feedUrl, { headers });
// If the feed hasn't changed, you do not need to update the store if (res.status === 304) { logger.info('Feed not modified, skipping'); return; } if (!res.ok || !res.body) { throw new Error(`Failed to fetch feed: ${res.statusText}`); }
// Store the last-modified header in the meta store so we can // send it with the next request meta.set('last-modified', res.headers.get('last-modified'));
// ... now store the data }, };}如果内容*确实*发生了变化,我们可以选择清除存储并完全替换它,或者如果数据源提供了这种级别的详细信息,则可以增量更新单个条目。
export function feedLoader({ url }: FeedLoaderOptions): Loader { const feedUrl = new URL(url); // Return a loader object return { // The name of the loader. This is used in logs and error messages. name: 'feed-loader', // The load method is called to load data load: async ({ store, logger, meta }) => { // Check if there's a last-modified time already stored const lastModified = meta.get('last-modified');
// If so, make a conditional request for the feed const headers = lastModified ? { 'If-Modified-Since': lastModified } : {};
const res = await fetch(feedUrl, { headers });
// If the feed hasn't changed, you do not need to update the store if (res.status === 304) { logger.info('Feed not modified, skipping'); return; } if (!res.ok || !res.body) { throw new Error(`Failed to fetch feed: ${res.statusText}`); }
// Store the last-modified header in the meta store so we can // send it with the next request meta.set('last-modified', res.headers.get('last-modified'));
const feed = parseFeed(res.body);
// If the loader doesn't handle incremental updates, clear the store before inserting new entries // In some cases the API might send a stream of updates, in which case you would not want to clear the store // and instead add, delete, or update entries as needed. store.clear();
for (const item of feed.items) { // The parseData helper uses the schema to validate and transform data const data = await parseData({ id: item.guid, data: item, });
// The generateDigest helper lets you generate a digest based on the content. This is an optional // optimization. When inserting data into the store, if the digest is provided then the store will // check if the content has changed before updating the entry. This will avoid triggering a rebuild // in development if the content has not changed. const digest = generateDigest(data);
store.set({ id, data, // If the data source provides HTML, it can be set in the `rendered` property // This will allow users to use the `<Content />` component in their pages to render the HTML. rendered: { html: data.description ?? '', }, digest, }); } }, };}何时*不*使用内容集合
以前,内容集合何时是一个好主意很清楚:只要您在页面中使用本地内容!内容层 API 为您提供了更多强大功能和灵活性,因为您可以将其用于任何内容源,包括实时 API。然而,重要的是要记住数据只在网站构建时更新,因此它不适用于所有用例。
这意味着当您的数据不经常变化时(例如博客),集合是完美的。如果您正在撰写一个托管在 CMS 中的博客,您可以在发布新帖子时通过 webhook 触发构建。内容层的增量更新应该会使构建速度变快。
这也适用于大多数电子商务网站,当产品被编辑时可以触发构建。如果您不介意等待部署网站以发布更新所需的时间,那么内容集合仍然是您的明确选择。您将获得最佳性能和出色的开发体验。
如果您需要页面近似实时更新或显示个性化内容,那么最好使用按需渲染适配器,最好配合 CDN 缓存头以确保页面加载速度超快。您甚至可以使用服务器岛屿将两者结合起来,获得两全其美的效果——使用内容集合渲染主要内容,并使用服务器岛屿处理实时或个性化内容。
下一步
内容层 API 是 Astro 的一大进步,但我们才刚刚开始。目前,数据存储只是一个键值存储,过滤功能有限。这虽然速度快,但内存效率不高,并且查询不够灵活。我们的目标是在未来版本中引入基于 Astro DB 的后端,以帮助其扩展到数十万个页面。它还将使我们能够支持更复杂的查询,甚至可能实现实时更新。
与此同时,我们非常乐意听取您对内容层 API 的反馈!尝试将您现有的网站迁移到使用它。(我们保证,这很容易!)并告诉我们进展如何。试用社区构建的一些新加载器,或者为您喜欢的 API 构建您自己的加载器。我们很高兴看到您用它构建出什么!